Önceki yazımızda, bir fonksiyona aktarılan parametre üzerinde değişklik yapmak istediğimizde bunun C#, Rust ve Zig programlama dilleri tarafındaki ele alınış biçimlerini farklı örneklerle incelemeye çalışmıştım. Nihayetinde ulaştığım noktada bir nesnenin kendisini tanımlayan değerlerin değiştirilmesinde programlama dili ve hatta kullanılacak yazılım mimarisi bazında farklı yaklaşımlar olduğunu görmüştük. Merak ettiğim bir başka konuysa, multi-thread(çoklu iş parçacığı) ortamlarında ortak veriyi değiştirmek. Aynı veri üzerinde birden fazla thread'in okuma/yazma işlemi yapması çok sık karşılaşılan bir durum. Şu anda elimde managed ortamı olan, yerleşik framework kütüphanelerinde üst düzey soyutlamalar sunan C#, bellek güvenliği konusundaki titiz stratejileri ve zorlamaları ile öne çıkan Rust ve C'nin modern bir versiyonu olarak gördüğüm düşük seviyeli sistem programlama dili Zig var.
Örnek kodların tamamına github adresinden ulaşabilirsiniz.
Önce C# Tarafı
Konuyu olabildiğince basit bir şekilde ele almak istiyorum. Söz gelimi aynı veri üzerine birden fazla thread'in yazmaya çalıştığı bir örnek düşünelim. Aşağıdaki kod parçası ile ilerleyebiliriz.
public class Program
{
static double CalculationResult = 0;
static void Main(string[] args)
{
Thread threadA = new(PerformCalculationsA);
Thread threadB = new(PerformCalculationsB);
threadA.Start();
threadB.Start();
threadA.Join();
threadB.Join();
Console.WriteLine($"Final Calculation Result: {CalculationResult}");
}
static void PerformCalculationsA()
{
for (int i = 0; i < 100; i++)
{
CalculationResult += Math.Sqrt(i);
Thread.Sleep(50);
}
}
static void PerformCalculationsB()
{
for (int i = 0; i < 100; i++)
{
CalculationResult += Math.Log(i + 1);
Thread.Sleep(50);
}
}
}
Bu programda CalculationResult isimli bir değişkene iki farklı thread tarafından yazma işlemi yapılıyor. Thread'ler tarafından işletilen metotlar kendi içlerinde açtıkları döngülerde hesaplama maliyeti yüksek sayılabilecek bir takım işlemler icra ediyor. Karekök alma ve logaritma hesaplamaları sırasında olayı daha da dramatize etmek içinse Sleep çağrıları ile gecikmeler oluşturuyoruz. Kendi sistemimde bu örneğin çalışma zamanı çıktıları aşağıdaki gibi oldu.
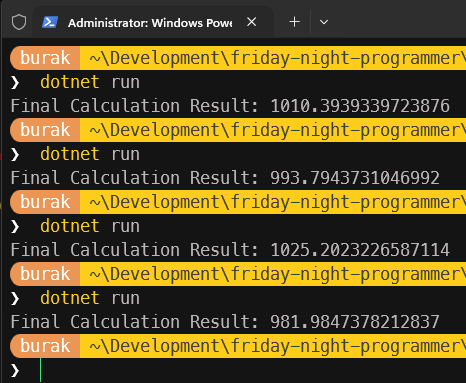
Aslında her seferinde aynı değerin oluşmasını bekliyordunuz değil mi? Ortada herhangi bir hata mesajı yok ama sonuçlar her seferinde farklı çıkıyor. Burada bir tahmin yürütüp bir thread söz konusu değişkene yazma işlemi yaparken diğer thread'in onu beklemesi böyle bir farka neden oluyor diyebiliriz. Yani içgüdüsel olarak thread' lerin aynı anda veriyi değiştirmesini engellemeyi tercih edebiliriz. Buna göre kodu aşağıdaki şekilde değiştirerek ilerleyelim.
using System.Threading;
public class Program
{
static double CalculationResult = 0;
static readonly Lock calculationLock = new();
static void Main(string[] args)
{
Thread threadA = new(PerformCalculationsA);
Thread threadB = new(PerformCalculationsB);
threadA.Start();
threadB.Start();
threadA.Join();
threadB.Join();
Console.WriteLine($"Final Calculation Result: {CalculationResult}");
}
static void PerformCalculationsA()
{
for (int i = 0; i < 100; i++)
{
double partialResult = Math.Sqrt(i);
lock (calculationLock)
{
CalculationResult += partialResult;
}
Thread.Sleep(50);
}
}
static void PerformCalculationsB()
{
for (int i = 0; i < 100; i++)
{
double partialResult = Math.Log(i + 1);
lock (calculationLock)
{
CalculationResult += partialResult;
}
Thread.Sleep(50);
}
}
}
Bu sefer sonuçlar tam da beklediğimiz gibi. Her seferinde aynı toplam değerini yakalıyoruz.
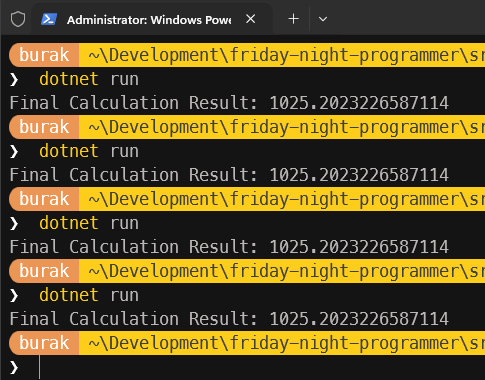
Yeni örneğimizde en basit kilit mekanizması olarak gördüğüm Lock nesnesini kullanıyorum. Her iki thread'in de ortak veriye erişmeden önce bu kilidi alması gerekiyor. Bir thread kilidi aldıktan sonra diğer thread'in söz konusu kilit serbest bırakılana kadar da beklemesi gerekiyor. Bu sayede aynı anda sadece tek bir thread ortak veriye erişip üzerinde değişiklik yapabiliyor. Bu da veri tutarlılığını sağlıyor. Bu zaten Mutual Exclusion(Karşılıklı Dışlama) prensibinin temel çalışma mantığı olarak düşünülebilir.
Elbette farklı kilit mekanizmaları ve stratejileri var. Örneğin, Reader-Writer Lock mekanizması ile birden fazla thread'in aynı anda okuma yapmasına izin verilip, yazma işlemi yapılacağı zaman tüm okuma işlemlerinin bitmesi beklenebilir. Bu tür stratejiler performans açısından da önemli olabilir. Ancak burada temel prensip olarak ortak veriye erişim sırasında veri tutarlılığını sağlamak için bir tür senkronizasyon mekanizması kullanılması gerekliliğidir. Interlocked sınıfı gibi daha düşük seviyeli atomik işlemler sunan yapılar da var. Aynı örneği birde Interlocked sınıfı kullanarak ele alalım.
using System.Threading;
public class Program
{
static double CalculationResult = 0;
static void Main(string[] args)
{
Thread threadA = new(PerformCalculationsA);
Thread threadB = new(PerformCalculationsB);
threadA.Start();
threadB.Start();
threadA.Join();
threadB.Join();
Console.WriteLine($"Final Calculation Result: {CalculationResult}");
}
static void PerformCalculationsA()
{
for (int i = 0; i < 100; i++)
{
double partialResult = Math.Sqrt(i);
double initialValue, computedValue;
do
{
initialValue = CalculationResult;
computedValue = initialValue + partialResult;
} while (Interlocked.CompareExchange(ref CalculationResult, computedValue, initialValue) != initialValue);
Thread.Sleep(50);
}
}
static void PerformCalculationsB()
{
for (int i = 0; i < 100; i++)
{
double partialResult = Math.Log(i + 1);
double initialValue, computedValue;
do
{
initialValue = CalculationResult;
computedValue = initialValue + partialResult;
} while (Interlocked.CompareExchange(ref CalculationResult, computedValue, initialValue) != initialValue);
Thread.Sleep(50);
}
}
}
Peki Ya Rust Tarafı?
Rust, sahiplik(ownership) ve borçlanma(borrowing) ilkeleri ile zaten bellek güvenliğini sıkı sıkıya denetlemeye çalışır. Benzer şekilde multi-thread ortamlarda veri yarışlarını önlemek için güçlü mekanizmalar da sunar. Ancak senaryoya ve ortak değişkene erişim şekline bağlı olarak(sadece okuma amaçlı, çok okuyucu-tek yazıcı vb.) farklı stratejiler izlemek gerekebilir. Burada karşımıza çıkan en yaygın çözümlerden birisi Arc(Atomic Reference Counting) ve Mutex(Mutual Exclusion) kombinasyonudur. İlk olarak önceki yazımızda da vurguladığımız gibi dotNetçi kafası ile hareket edelim. Bu noktada kodu pekala aşağıdaki gibi yazsak olur.
use std::thread;
fn main() {
let mut calculation_result: f64 = 0.0;
let handle_1 = std::thread::spawn(|| {
for i in 1..=100 {
calculation_result += (i as f64).sqrt();
thread::sleep(std::time::Duration::from_millis(50));
}
});
let handle_2 = std::thread::spawn(|| {
for i in 1..=100 {
calculation_result += (i as f64 + 1.0).ln();
thread::sleep(std::time::Duration::from_millis(50));
}
});
handle_1.join().unwrap();
handle_2.join().unwrap();
println!("Calculation result {}", calculation_result);
}
Yazım stili farklılaşsa da benzer bir işleyiş olduğunu söyleyebilirim. handle_1 ve handle_2 isimliye yumurtlanan thread'ler ortak değişken olan calculation_result üzerinde yazma işlemi yapıyor. Ne varki bu kodu çalıştıramayacağız zira derleyici bizi aşağıdaki ekran görüntüsünde olduğu gibi üzecek.
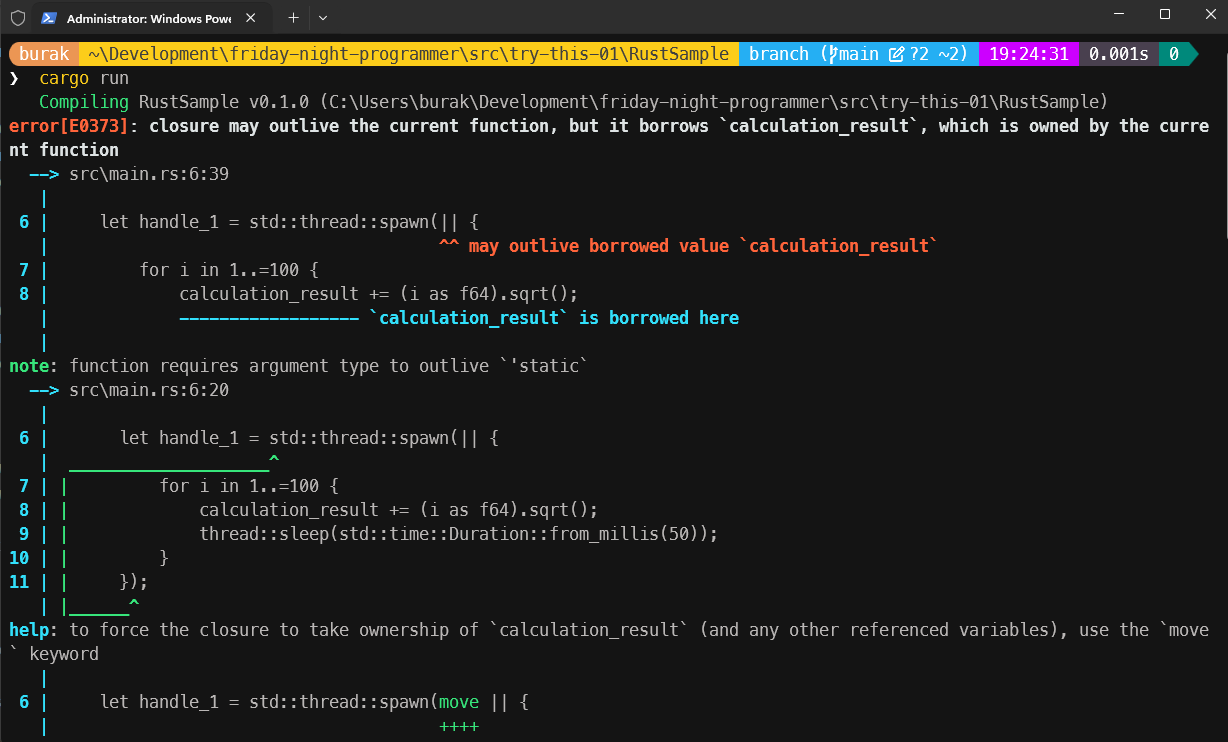
Bu son derece doğal, zira oluşturulan thread'ler kendi kapsamlarında bir üst thread olan main'deki bir değişkeni kullanma niyetindeler. Bunu açıkça ifade etmemiz bekleniyor ve bunun yolu da move operatörünün kullanılmasından geçiyor. Dolayısıyla söz konusu kodları aşağıdaki gibi değiştirerek ilerlememiz lazım.
use std::thread;
fn main() {
let mut calculation_result: f64 = 0.0;
let handle_1 = std::thread::spawn(move || {
for i in 1..=100 {
calculation_result += (i as f64).sqrt();
thread::sleep(std::time::Duration::from_millis(50));
}
});
let handle_2 = std::thread::spawn(move || {
for i in 1..=100 {
calculation_result += (i as f64 + 1.0).ln();
thread::sleep(std::time::Duration::from_millis(50));
}
});
handle_1.join().unwrap();
handle_2.join().unwrap();
println!("Calculation result {}", calculation_result);
}
Bu sefer program sorunsuz şekilde çalışacaktır ancak sonuçlar hiç de beklediğimiz gibi olmayacaktır. Programı kaç kez çalıştırırsak çalıştıralım her seferinde 0(yazıyla sıfır) sonucunu elde ederiz :D Üstelik Rust derleyicisi calculation_result değişkeninin hiç kullanılmadığını bile iddia eder.
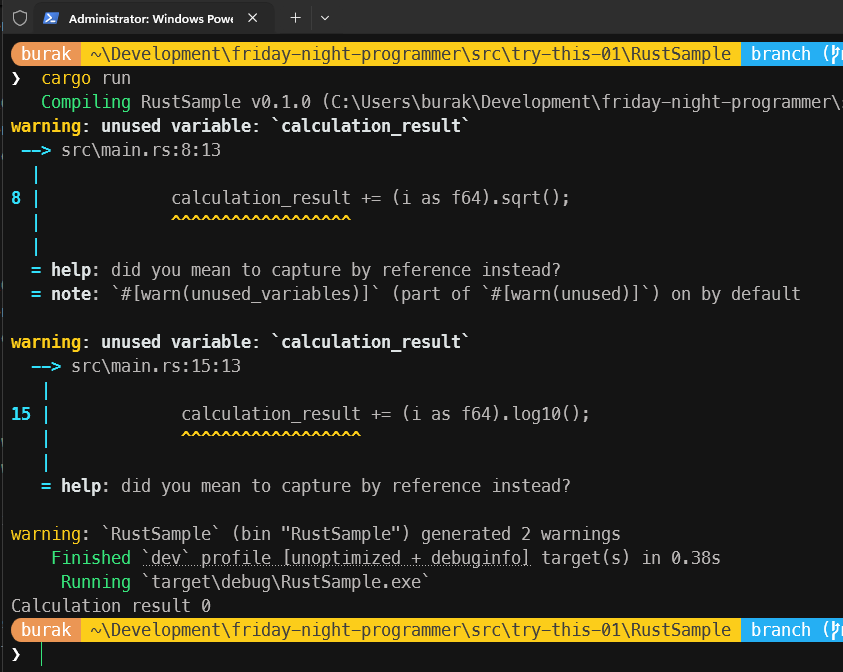
Bu durum kısa bir açıklamayı gerektiriyor. move operatörü ile main thread içerisindeki calculation_result değişkeni açılan thread scope'larına kopyalanarak taşınır. Yani her thread kendi calculation_result kopyasına sahip olarak çalışır. Dolayısıyla += operatörünü main thread içerisindeki calculation_result değişkenine uyguluyor gibi görsek de bu aslında o scope içerisine alınmış kopya üzerinde yapılan bir işlem. Gelin bu teoriyi ispat etmeye çalışalım. Bu amaçla kodu aşağıdaki gibi değiştirelim.
use std::thread;
fn main() {
let mut calculation_result: f64 = 0.0;
let handle_1 = std::thread::spawn(move || {
for i in 1..=100 {
calculation_result += (i as f64).sqrt();
thread::sleep(std::time::Duration::from_millis(50));
println!("Intermediate result from Handle 1 {}", calculation_result);
}
});
let handle_2 = std::thread::spawn(move || {
for i in 1..=100 {
calculation_result += (i as f64 + 1.0).ln();
thread::sleep(std::time::Duration::from_millis(50));
println!("Intermediate result from Handle 2 {}", calculation_result);
}
});
handle_1.join().unwrap();
handle_2.join().unwrap();
println!("Calculation result {}", calculation_result);
}
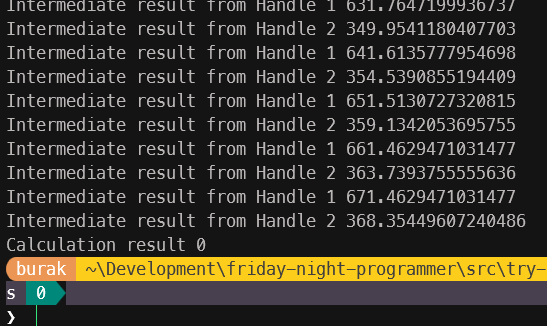
Tabii bu benim bakış açımdan bir ispat. Açılan her handle scope'u kopyalayarak aldığı calculation_result değişkeni üzerinde işlemler yapıyor ve kendi ara sonuçlarını yazdırıyor. Ama aynı şey main thread içindeki calculation_result değeri için geçerli değil. Burada calculation_result değişkeninin f64 türünden olduğunu ve Copy trait'ini implemente ettiğini hatırlatayım. O halde bu işi Rust tarafında istediğimiz şekilde ele almak için de birşeyler yapmamız gerekiyor. Her şeyden önce ortak verinin iki thread içerisinde de kullanılabiliyor olması lazım. Bunun için genellikle Atomic Reference Counting(Arc) isimli akıllı işaretçi(smart pointer) kullanılmakta.
Arc enstrümanı bir verinin birden fazla sahibi olmasına olanak tanır ve bunun için referans sayımı yaparak belleğin doğru şekilde yönetilmesini sağlar. Ancak Arc tek başına yeterli değildir çünkü aynı anda birden fazla thread'in veriyi değiştirmesine izin verilmez. Bu nedenle Mutex(Mutual Exclusion) yapısını da kullanmamız gerekir. Mutex, aynı anda sadece bir thread'in veriye erişmesine izin verir ve böylece data race durumu önlenir. Aynen .net tarafında Lock ile yaptığımız gibi. Bu kombinasyonun uygulanışından önce söz konusu senaryoda Arc bileşenini Mutex olmadan kullanmayı deneyelim.
use std::thread;
// CASE02: Bu senaryoda Arc'ı tek başına Mutex olmadan kullanırsak.
use std::sync::Arc;
fn main(){
let calculation_result = Arc::new(0.0_f64);
let calc_res_clone_1 = Arc::clone(&calculation_result);
let handle_1 = thread::spawn(move || {
for i in 1..=100 {
*calc_res_clone_1 += (i as f64).sqrt();
thread::sleep(std::time::Duration::from_millis(50));
}
});
let calc_res_clone_2 = Arc::clone(&calculation_result);
let handle_2 = thread::spawn(move || {
for i in 1..=100 {
*calc_res_clone_2 += (i as f64 + 1.0).ln();
thread::sleep(std::time::Duration::from_millis(50));
}
});
handle_1.join().unwrap();
handle_2.join().unwrap();
println!("Calculation result {}", *calculation_result);
}
Programı bu şekilde çalıştırdığımızda derleyicinin kırıcı mesajları ile başbaşa kalırız.
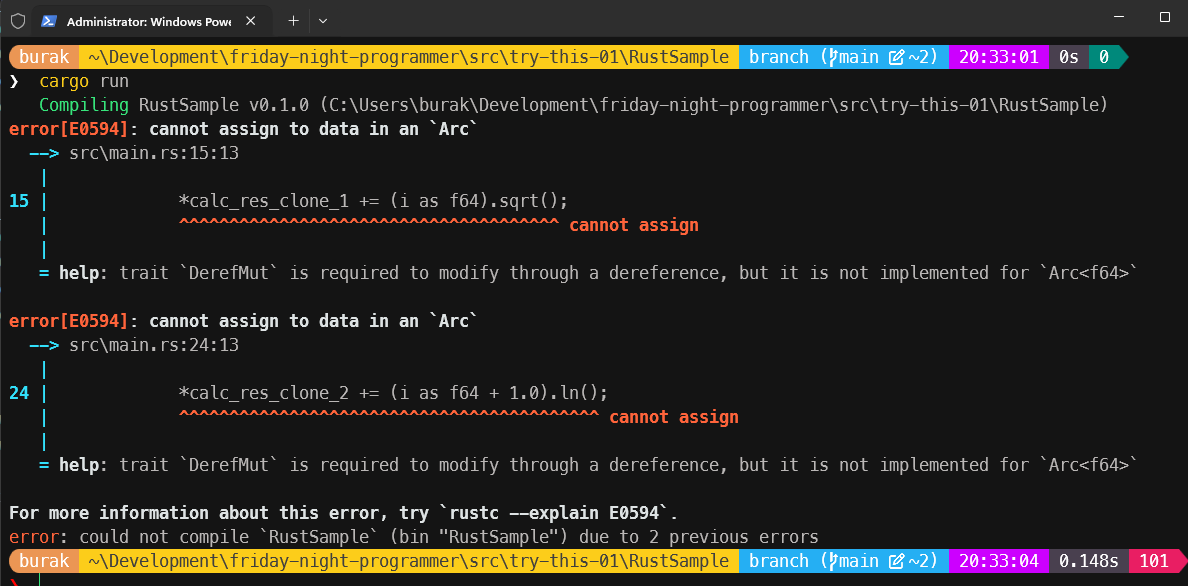
Bu mesajlar ilk etapta anlamsız gibi görünse de tam olarak konuyla ilgilidir. cannot assign to data in an Arc ifadesini takiben söylenen trait DerefMut is required to modify through a dereference, but it is not implemented for Arc<f64> mesajı Arc ile sarmalanmış bir veriyi değiştirmek için gerekli olan DerefMut trait'inin implemente edilmediğini söyler. Yani Arc tek başına ortak veriyi değiştirmek için yeterli değildir, zira o sadece Deref trait'ini implemente etmektedir. Bize gerekli olan şeyse DerefMut implementasyonu. Bunu da Mutex kullanarak sağlayabiliriz.
use std::thread;
use std::sync::Arc;
fn main(){
let calculation_result = Arc::new(std::sync::Mutex::new(0.0_f64));
let calc_res_clone_1 = Arc::clone(&calculation_result);
let handle_1 = thread::spawn(move || {
for i in 1..=100 {
let mut result = calc_res_clone_1.lock().unwrap();
*result += (i as f64).sqrt();
thread::sleep(std::time::Duration::from_millis(50));
}
});
let calc_res_clone_2 = Arc::clone(&calculation_result);
let handle_2 = thread::spawn(move || {
for i in 1..=100 {
let mut result = calc_res_clone_2.lock().unwrap();
*result += (i as f64 + 1.0).ln();
thread::sleep(std::time::Duration::from_millis(50));
}
});
handle_1.join().unwrap();
handle_2.join().unwrap();
println!("Calculation result {}", *calculation_result.lock().unwrap());
}
Tabii kilitleri açık bir şekilde serbest bırakmak için bir kod kullanmadık ancak scope sonları zaten bu işin otomatik yapılmasını sağlayacaktır. İşte çalışma zamanı çıktısı.
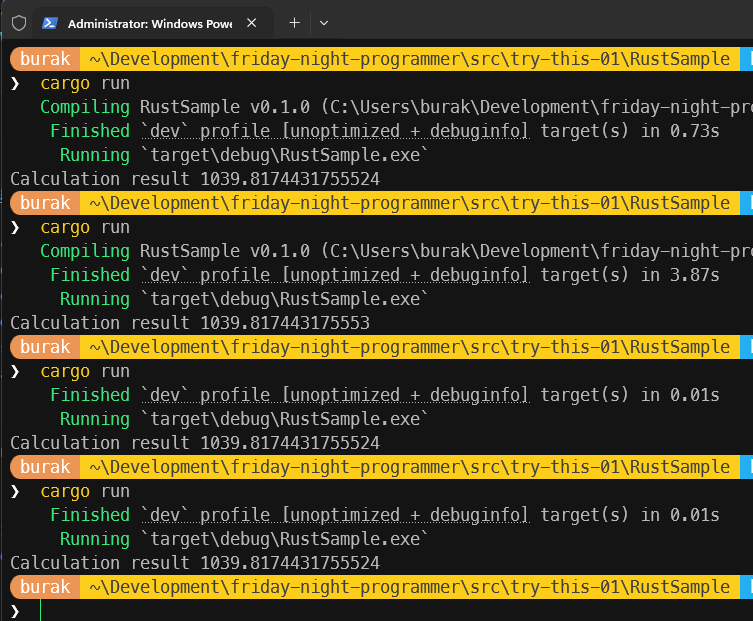
Ay now, ay now... Tuhaf bir durum söz konusu. Yüksek hassasiyetli 64 bit floating point değer her deneme için %100 tutarlı değil gibi görünüyor. Örneğin ikinci denemede son küsürat bir üst değere yuvarlanmış. Alt alta yazınca fark daha net görülebilir.
1039.8174431755524
1039.817443175553
Üstelik .Net tarafındaki gibi iki thread ve her birisinde 100er iterasyon içeren döngülerde çalışırken... Buradaki farkın karekök ve logaritma işlemlerinden kaynaklanan küçük yuvarlama hatalarından mı yoksa Mutex kilitlenmesi sırasında ortaya çıkan performans etkilerinden mi kaynaklandığını bilmiyorum. Belki de her ikisi birden. Ancak sonuçların her seferinde aynı olmaması dikkat çekici. Bir nevi thread'lerin farklı sıralarda çalışmasından kaynaklı bir durum da söz konusu olabilir. Sadece üstünkörü bir bakış açısıyla Rust tarafındaki hesaplamaların daha yüksek rakamlara ulaştığını ifade edebiliriz.
Zig Tarafı
Gelelim yeni yeni öğrenemye çalıştığım Zig tarafına. Zig tarafında thread açmak ve mutex kullanımı da oldukça basit. Rust dilindekine benzer şekilde bir spawn fonksiyonu var ve Thread modülü altında tanımlanmış durumda. Yukarıdaki senaryomuzun bir benzerini başlangıçta herhangibir data race tedbiri almadan aşağıdaki şekilde yazabiliriz.
const std = @import("std");
pub fn main() !void {
var calculation_result: f64 = 0.0;
const handle_1 = try std.Thread.spawn(
.{},
calcSqrt,
.{&calculation_result},
);
const handle_2 = try std.Thread.spawn(
.{},
calcLn,
.{&calculation_result},
);
handle_1.join();
handle_2.join();
std.debug.print("Calculation result {d}\n", .{calculation_result});
}
fn calcSqrt(value: *f64) void {
for (1..100) |i| {
value.* += std.math.sqrt(@as(f64, @floatFromInt(i)));
std.time.sleep(50 * std.time.ns_per_ms);
}
}
fn calcLn(value: *f64) void {
for (1..100) |i| {
value.* += std.math.log2(@as(f64, @floatFromInt(i)) + 1.0);
std.time.sleep(50 * std.time.ns_per_ms);
}
}
Aslında Thread başlatırken Rust kodunda olduğu gibi fonksiyonu bloğunu bir closure mantığında spawn metodunda kullanmak istememe rağmen başaramadım. Zira spawn metodu ikinci parametre olarak fonksiyon referansı bekliyor. Bu nedenle karekök ve logaritma hesaplamalarını yapan fonksiyonları ayrı ayrı tanımladım(ki bu belkide kodun okunabilirliği ya da sorumlulukların doğru dağıtılması adına iyi bir yaklaşımdır) Her iki fonksiyon da kendilerine aktarılan f64 türünden nesne işaretçisi üzerinden aynı değişken verisini değiştiriyor. Program kodu herhangi bir hata vermeden çalıştı ve kendi sistemimde aşağıdaki ekran görüntüsündekine benzer çıktılar elde ettim.
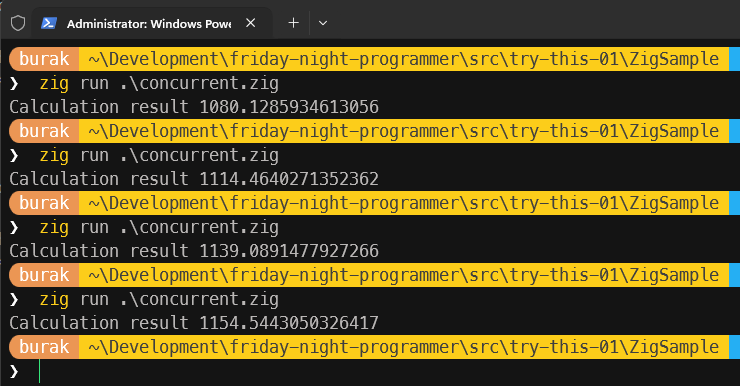
Diğer örneklerdeki değerlere yakın sonuçlar elde etsem de kendi özelinde değerlendirdiğimizde her seferinde farklı sonuçlar elde etmemiz son derece normal. Zira her thread işletim sisteminin de desteğiyle farklı zamanlarda çalışarak aynı ortak veri üzerinde değişiklik yapmakta. Zig dilinde de bu tip senaryolarda verinin tutarlığını sağlamak ve her seferinde aynı sonuçlara ulaşmak için yine bir senkronizasyonu mekanizmasına başvurmamız gerekiyor ve burada da tahmin edeceğiniz üzere Mutex devreye giriyor(Birde RwLock var) Aynı kod parçasında bu sefer Mutex tabanlı kilit fonksiyonlarını kullanarak ilerleyelim.
const std = @import("std");
// CASE 01 : Mutext ile ortak veri üzerinde thread işlemi
pub fn main() !void {
var guard = std.Thread.Mutex{};
var calculation_result: f64 = 0.0;
const handle_1 = try std.Thread.spawn(
.{},
calcSqrt,
.{ &calculation_result, &guard },
);
const handle_2 = try std.Thread.spawn(
.{},
calcLn,
.{ &calculation_result, &guard },
);
handle_1.join();
handle_2.join();
std.debug.print("Calculation result {d}\n", .{calculation_result});
}
fn calcSqrt(value: *f64, guard: *std.Thread.Mutex) void {
for (1..100) |i| {
guard.lock();
value.* += std.math.sqrt(@as(f64, @floatFromInt(i)));
std.time.sleep(50 * std.time.ns_per_ms);
guard.unlock();
}
}
fn calcLn(value: *f64, guard: *std.Thread.Mutex) void {
for (1..100) |i| {
guard.lock();
defer guard.unlock();
value.* += std.math.log2(@as(f64, @floatFromInt(i)) + 1.0);
std.time.sleep(50 * std.time.ns_per_ms);
}
}
Senaryo burada biraz daha kolay kurgulandı sanki. Bir Mutex değişkeni tanımladık ve söz konusu değişkeni spawn metodu üzerinden ilgili fonksiyonlara referans olarak aktardık. Her iki fonksiyonda da değişken değerini değiştirmeden hemen önce ve sonra sırasıyla kilit koyma ve serbest bırakma işlemlerini icra ettik. Aslında sembolik duraksatma sürelerini unlock çağrılarının hemen arkasına da alabilirdik ama Rust tarafındaki kod parçasında döngü kapsamı bittiği noktada unlock çalışacak şekilde kodlama yaptığımdan burada da benzer şekilde ilerlemek istedim. Dikkat etmişsinizdir calcLn fonksiyonu içerisinde unlock işlemi için defer ifadesi kullanılıyor. Yani iterasyonda devam ederken kilit otomatik olarak unlock çağrısı yapılmadan serbest kalıyor. Bunu sadece bir örnek olsun diye ekledim. Bazen aynı thread içerisindeki kod bloklarında satır sayısı çok fazla olabilir. En başta defer ile unlock bildiriminde bulunmak kodun okunabilirliği açısından faydalı olur. Gelelim çalışma zamanı çıktısına. Kendi sistemimde elde ettiğim sonuçlar aşağıdaki ekran görüntüsünde olduğu gibi.
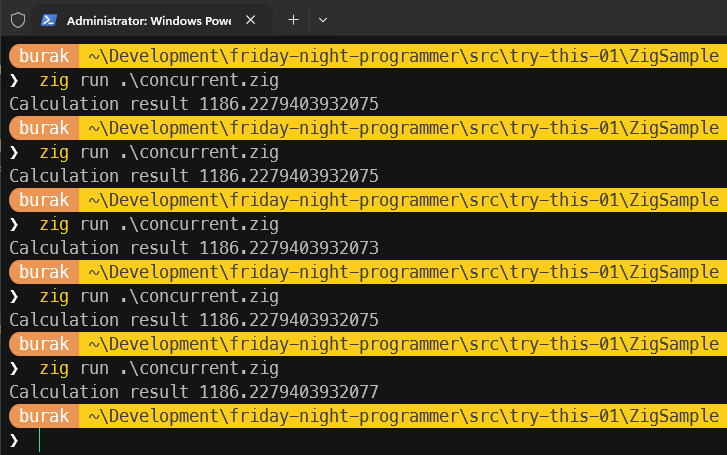
Hatırlarsanız Rust tarafındaki kilitleme örneğinde de benzer bir durum söz konusuydu. Küsüratlarda ara sıra sapmalar yaşanmakta. Ancak genel olarak Zig tarafındaki sonuçların Rust tarafındaki sonuçlara daha yakın olduğunu söyleyebilirim. Yine de her iki dilde de thread'lerin çalışma zamanlarındaki farklılıklardan ötürü tam olarak aynı sonuçları elde etmek mümkün olmayabilir.
Zig tarafı için not: Eş zamanlı yazma/okuma süreçlerinde Mutex dışında daha verimli olabilecek bir seçenek daha var; RwLock. RwLock enstrümanı ile okuma amaçlı erişimler sırasında lockShared ve unlockShared metotları ile yazma operasyonuna göre daha az maliyetli bir kilitleme akışı sağlamanın mümkün olduğu ifade ediliyor. learning-zig repomda bu konuya dair bir örnek mevcut. Ancak buradaki akışta amacım temel kilitleme mekanizmasını göstermek olduğu için RwLock kullanımına değinmedim.
Başka Nelere Bakmalı?
Bu örnekte ele aldığımız senaryo son derece basit, gerçek anlamda kullanılabilir değil ve teoriden öteye geçmez nitelikte. Yine de ortak verinin değiştirileceği durumlarda basit kilit mekanizmalarının C#, Rut ve Zig özelinde nasıl ele alındığını bir dokümanda birleştirmiş olduk. Bu senaryolarda belki çalışma zamanını ölçümleyen ve testleri tekrarlı olarak icra eden mekanikler kullanarak ortaya çıkan sonuçları istatistiki anlamda değerlendirmek daha anlamlı olabilir. Performans/Maliyet açısından da hem birbirlerine göre hem de kendi içlerinde ne gibi sonuçlar ürettiklerini değerlendirebiliriz. Zira fark ediliyor ki, kilit mekanizmalarını devreye aldığımız anda toplam işlem süreleri de uzuyor ki bu çok normal. Ancak öyle senaryolar olabilir ki veri kaybını göze alabiliriz ve bu durumda kilitleme mekanizmalarını da kullanmayız ya da Read-Write Lock gibi daha performanslı çözümler tercih edebiliriz.
Ne yazık ki hayat böylesine toz pembe değil. Özellikle değiştirilebilir(mutable) verilerin çevrimiçi(online) platformlardan erişildiği kullanımlarda çok daha karmaşık çözümler gerekiyor. Bu tip senaryolar aynı makinedeki thread'ler arasındaki yarıştan çok, dağıtık ağ ortamındaki makinelerin işin içerisine girdiği durumları düşünmemizi gerektiriyor. Ölçekleme(scaling) ise işin bambaşka bir boyutu. Çözüm olarak genellikle dağıtık kilit mekanizmaları, veri tabanı tabanlı kilitleme stratejileri veya mesaj tabanlı senkronizasyon çözümleri ele alınıyor.
Örneğin, Redis gibi in-memory çalışan ve bunu dağıtık ölçekte performanslı bir şekilde ele alan ürünler sıklıkla tercih ediliyor. Diğer yandan, mikroservis mimarilerinde olay güdümlü(event-driven) iletişim için değerlendirilen mesaj kuyruğu sistemleri de(RabbitMQ gibi) veri tutarlılığını sağlamak için düşünülebilir. Bu tip senaryoları değerlendirmek için farklı bir laboratuvar ortamı tesis etmek lazım. Zira az önce de değindiğim üzere olay thread'ler arası değil uygulamalar arası bir senkronizasyonu da gerektiriyor. Setup'ı çok kolay olmayabilir belki ama ilerleyen zamanlarda bu konulara da değinmek istiyorum.
Örnek kodların tamamına github adresinden ulaşabilirsiniz.
Şimdilik bu kadar. Böylece geldik bir denememizin daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.